Research Goal
To build a never-ending machine learning system that acquires the ability to extract structured information from unstructured web pages. If successful, this will result in a knowledge base (i.e., a relational database) of structured information that mirrors the content of the Web. We call this system NELL (Never-Ending Language Learner).
Approach
The inputs to NELL include (1) an initial ontology defining hundreds of categories (e.g., person, sportsTeam, fruit, emotion) and relations (e.g., playsOnTeam(athlete,sportsTeam), playsInstrument(musician,instrument)) that NELL is expected to read about, and (2) 10 to 15 seed examples of each category and relation.
Given these inputs, plus a collection of 500 million web pages and access to the remainder of the web through search engine APIs, NELL runs 24 hours per day, continuously, to perform two ongoing tasks:
- Extract new instances of categories and relations. In other words, find noun phrases that represent new examples of the input categories (e.g., "Barack Obama" is a person and politician), and find pairs of noun phrases that correspond to instances of the input relations (e.g., the pair "Jason Giambi" and "Yankees" is an instance of the playsOnTeam relation). These new instances are added to the growing knowledge base of structured beliefs.
- Learn to read better than yesterday. NELL uses a variety of methods to extract beliefs from the web. These are retrained, using the growing knowledge base as a self-supervised collection of training examples. The result is a semi-supervised learning method that couples the training of hundreds of different extraction methods for a wide range of categories and relations. Much of NELL’s current success is due to its algorithm for coupling the simultaneous training of many extraction methods.
For more in-depth details, see our list of research publications.
A Brief History of NELL
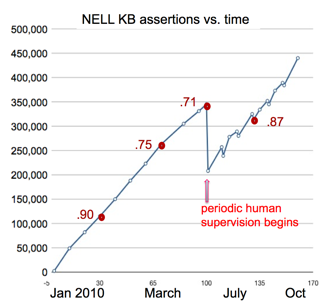
NELL has been in continuous operation since January 2010. For the first 6 months it was allowed to run without human supervision, learning to extract instances of a few hundred categories and relations, resulting in a knowledge base containing approximately a third of a million extracted instances of these categories and relations. At that point, it had improved substantially its ability to read three quarters of these categories and relations (with precision in the range 90% to 99%), but it had become inaccurate in extracting instances of the remaining fourth of the ontology (many had precisions in the range 25% to 60%).
The estimated precision of the beliefs it had added to its knowledge base at that point was 71%. We are still trying to understand what causes it to become increasingly competent at reading some types of information, but less accurate over time for others. Beginning in June, 2010, we began periodic review sessions every few weeks in which we would spend about 5 minutes scanning each category and relation. During this 5 minutes, we determined whether NELL was learning to read it fairly correctly, and in case not, we labeled the most blatant errors in the knowledge base. NELL now uses this human feedback in its ongoing training process, along with its own self-labeled examples. In July, a spot test showed the average precision of the knowledge base was approximately 87% over all categories and relations. We continue to add new categories and relations to the ontology over time, as NELL continues learning to populate its growing knowledge base.
At present, NELL has accumulated a knowledge base of 2,810,379 asserted instances of 1,186 different categories and relations.
To track NELL’s progress, browse the knowledge base and the summary of its content.